ubuntu目前22.04和24.04在线安装mysql8会出现无法修改密码,或者密码修改提示成功,但是依然可以使用空密码登陆的问题,导致这个问题的原因是因为默认使用auth_socket这个插件导致,使用这个插件意味着...
ubuntu目前22.04和24.04在线安装mysql8会出现无法修改密码,或者密码修改提示成功,但是依然可以使用空密码登陆的问题,导致这个问题的原因是因为默认使用auth_socket这个插件导致,使用这个插件意味着...
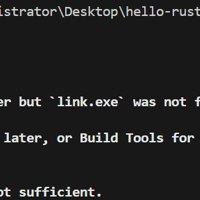
刚部署完rust在vscode中进行调试就报错,错误代码如下这个错误由于使用了错误的工具链导致,我们需要安装stable-x86_64-pc-windows-msvc这个工具链,然后进行切换。查看当前默认工具链rustu...
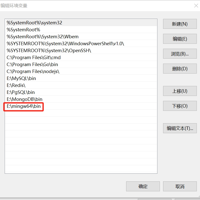
由于rust需要C语言环境,我们需要安装VisualStudio来提供本地的C语言环境,但是VisualStudio比较大,安装时间较长,所以我们这里选择另一种方式,就是部署mingw64来搭建C语言环境mingw64下...
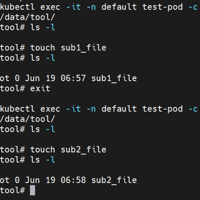
我们之前使用k8s的时候一般都是POD由Controller来分配IP地址,如果我们想固定地址,一般都是使用hostnetwork:true等配置来使用宿主机的地址,再或者直接配置service来配置svc访问的地址,这...
之前在centos7上编译安装过mysql8,这次记录下在ubuntu22.04上编译安装的过程,编译软件版要求和约束路径都和centos一样,可以查看之前的笔记:https://sulao.cn/post/775安装包...
之前在centos上编译过,目前基本都转到ubuntu22.04了,所以在这个版本上进行编译部署并记录下来。首先我们更新系统apt包,并安装编译时需要的依赖包sudo apt update sudo apt instal...
之前有在centos上部署k8s集群的时候离线安装过containerd,但是目前看来后面使用ubuntu比较多,所以记录下在ubuntu22.04上离线安装containerd的方法,实际上containerd在发布2...
我看到我博客还没记录离线安装docker的笔记,所以这次本地实践了下顺便记录下如何安装和配置。首先我们需要去ubuntu官网上下载docker离线tar.gz包,目前最新版本是docker-28.0.4.tgz,如果没有...
因为有很多私有云项目需要安装指定版本的软件需求,例如公司产品只适配了某些版本的docker,所以就需要在系统中安装指定版本的docker,那么这里就记录下ubuntu22.04安装指定版本的docker的方法。1.安装依...
Gunicorn的优化需要结合当前硬件资源以及WEB业务的场景来进行优化配置,例如CPU密集型和IO密集型两种场景他们对进程数和是否要开启异步的需求是不一样的,下面我就来介绍一下针对这些场景的优化方案。1.CPU密集型场...
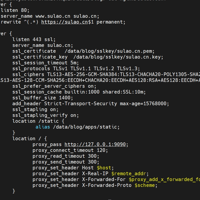
使用nginx代理发布flask应用以后基本都会遇到这两个问题,以下就是解决方法,记录以后方便使用1.web前端无法加载静态资源图片这个需要在nginx中添加静态资源访问的别名地址location /static { ...
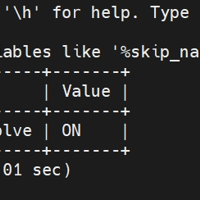
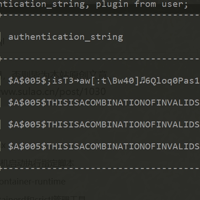
mysql根据以前的配置进行优化,优化完以后发现登录报错,提示以下错误信息Enter password: ERROR 1130 (HY000): Host '127.0.0.1' is not allowed to co...
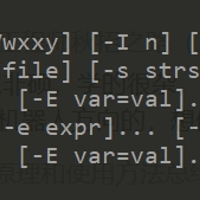
strace命令是一个集诊断、调试、统计于一体的工具,我们可以用它来监控用户空间进程和内核的交互。比如对应用程序的系统调用、信号传递与进程状态变更等进行跟踪与分析,以达到解决问题的目的。strace常用来跟踪进程执行时的...
通常在一个集群会有一个统一的API入口,一般都是使用nginx来做统一的入口代理,然后到后端再转发到对应的服务API上。今天就整合之前的一些代理的配置,方便后续使用。1.nginx代理http/https请求http {...
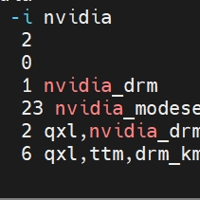
日常在一些程序中进行GPU调用,这些cuda程序异常崩溃的时候,有时会遇到掉卡掉驱动、没有进程但是显存被占用的情况,这个时候我们可以通过以下命令来尝试进行处理。如果是掉卡的话可以使用lspci查看下主板上还能否检测到GP...
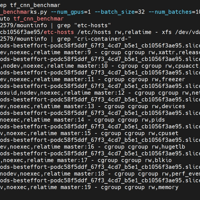
之前我们有记录过一个笔记,是docker环境下通过查看到的进程PID号来查找到拥有该进程的POD,具体可以查看我之前的笔记:https://sulao.cn/post/922近期基本都在将docker环境切换到conta...