
NCCL Tests是一个开源的测试套件,由NVIDIA开发并维护,目的是为了帮助开发者更好地理解和利用NCCL的功能。它提供了多种并发和消息传递模式的基准测试,以评估多GPU间的通信效率,并且支持各种CUDA和MPI环境。
我们在多机多卡进行测试的时候确保环境中高性能网络已经部署并配置好,注意,如果没有IB之类的高性能网络支持,多机多卡通信效率肯定会很低,延迟大。
NCCL可以加速GPU通信,降低通信开销,它允许两个特定的GPU之间直接交换数据,同时NCCL还支持集体通信,这些操作涉及多个GPU之间的数据交换。
集合通讯模式
1.P2P(Point-to-point communication)
1).单一发送方,单一接收方
2).高效通信相对好实现
P2P是HPC中最常见的模式,其中通信通常是与最近的邻居
2.CC(Collective communication)
1).多个发送方和/或接收方
2).模式有broadcast, scatter, gather, reduce, all-to-all等等
3).很难做到高效
我们还是需要首先进行环境的搭建,需要依次安装cuda、nccl、mpi、ncc-test,环境部署可以查看我之前的笔记:https://sulao.cn/post/987
我们下载nccl-test源码进行编译安装,可以到这里查找一个nccl-test的使用相关信息:https://github.com/NVIDIA/nccl-tests
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make MPI=1 MPI_HOME=/usr/local/openmpi CUDA_HOME=/usr/local/cuda-11.8 NCCL_HOME=/usrCUDA_HOME根据实际原生CUDA库路径进行修改,如果nccl没有安装到默认路径下,那么需要添加NCCL_HOME变量,值根据实际路径进行修改。
编译完成以后,build目录会生成如下二进制文件

每个二进制文件功能如下:
all_gather_perf:测试 all-gather 操作的性能,在all-gather操作中,每个节点都有一个值,然后这些值被收集到一个列表中,然后这个列表被发送回所有的节点
all_reduce_perf:测试 all-reduce 操作的性能,在 all-reduce 操作中,所有的节点都有一个输入值,然后这些值被归约(例如,通过求和或者求最大值)成一个单一的值,然后这个值被发送回所有的节点
alltoall_perf:测试 all-to-all 操作的性能,在 all-to-all 操作中,每个节点都发送一个值给所有其他的节点,并从所有其他的节点接收一个值
broadcast_perf:测试 broadcast 操作的性能,在 broadcast 操作中,一个节点有一个值,然后这个值被发送到所有其他的节点
gather_perf:测试 gather 操作的性能,在 gather 操作中,每个节点都有一个值,然后这些值被收集到一个列表中,然后这个列表被发送到一个指定的节点
hypercube_perf:测试 hypercube 通信模式的性能,在 hypercube 通信模式中,节点被组织成一个超立方体的结构,然后在这个结构中进行通信
reduce_perf:测试 reduce 操作的性能,在 reduce 操作中,所有的节点都有一个输入值,然后这些值被归约成一个单一的值,然后这个值被发送到一个指定的节点
reduce_scatter_perf:测试 reduce-scatter 操作的性能,在 reduce-scatter 操作中,所有的节点都有一个输入值,然后这些值被归约成一个单一的值,然后这个值被分散到所有的节点
scatter_perf:测试 scatter 操作的性能,在 scatter 操作中,一个节点有一个列表的值,然后这些值被分散到所有其他的节点
sendrecv_perf:测试 point-to-point 通信的性能测试单节点1卡,实际单机可以直接使用nccl-tests内工具进行直接测试,跨节点才需要用到openmpi
export LD_LIBRARY_PATH=/usr/local/openmpi/lib/:$LD_LIBRARY_PATH mpirun -np 1 --allow-run-as-root ./build/all_reduce_perf -b 1M -e 8G -f 2 -g 1

上述np 1代表1个进程,-b 1M代表数据量从1M开始,到-e 128M也就是128M结束,-f 2就是每次增加的倍数,-g是每个线程的gpu数量,如果是root用户执行需要添加--allow-run-as-root参数,mpi默认是不允许root账户执行。
单机测试的话直接使用all_reduce_pref进行测试,例如下面单机4卡,根据自己的卡的数量修改-g参数的值,测试其他pref工具,直接修改工具名字,即可,参数均是一致的。
./build/all_reduce_perf -b 1M -e 8G -f 2 -g 4mpirun 是一个用于启动和管理 MPI(消息传递接口)程序的实用程序。它允许您在单个节点或多个节点上并行运行程序
完整的参数如下:
-t,--nthreads <num threads> 每个进程的线程数量配置, 默认 1
-g,--ngpus <GPUs per thread> 每个线程的 GPU数量,默认 1
-b,--minbytes <min size in bytes> 开始的最小数据量,默认32M
-e,--maxbytes <max size in bytes> 结束的最大数据量,默认 32M
-i,--stepbytes <increment size> 每次增加的数据量. 默认: 1M
-f,--stepfactor <increment factor> 每次增加的倍数. 默认禁用
-o,--op <sum/prod/min/max/avg/all>指定那种操作为reduce,仅适用于Allreduce、Reduce或ReduceScatter等缩减操作。默认值为:求和(Sum)
-d,--datatype <nccltype/all>指定使用哪种数据类型. 默认 : Float
-r,--root <root/all>指定使用哪个 root 用户,默认0
-n,--iters <iteration count> 每次操作(一次发送)循环多少次. 默认 : 20.
-w,--warmup_iters <warmup iteration count> 预热迭代次数(不计时)。默认值为:5
-m,--agg_iters <aggregation count> 每次迭代中要聚合在一起的操作数。默认值为:1
-a,--average <0/1/2/3> 在所有ranks计算均值作为最终结果 (MPI=1 only). <0=Rank0,1=Avg,2=Min,3=Max>. 默认为 1
-p,--parallel_init <0/1> 使用线程并行初始化 NCCL, 默认 : 0
-c,--check <0/1> 检查结果的正确性。在大量GPU上可能会非常慢。默认值为:1
-z,--blocking <0/1> 使NCCL集合阻塞,即在每个集合之后让CPU等待和同步。默认值为:0
-G,--cudagraph <num graph launches> 将迭代作为CUDA图形捕获,然后重复指定的次数。默认值为:02台GPU节点,8张GPU卡启动命令如下:
mpirun -np 8 \
-H 192.168.1.72:4,192.168.1.73:4 \
--allow-run-as-root -bind-to numa -map-by slot \
-x NCCL_DEBUG=INFO \
-x NCCL_ALGO=Ring \
-x NCCL_MAX_NCHANNELS=16 \
-x NCCL_MIN_NCHANNELS=16 \
-x NCCL_IB_HCA=mlx5_0,mlx5_1 \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_IB_DISABLE=0 \
-x NCCL_IB_RETRY_CNT=7 \
-x NCCL_IB_TIMEOUT=23 \
-x NCCL_SOCKET_IFNAME=eth0 \
-x NCCL_NET_GDR_LEVEL=2 \
-x NCCL_IB_QPS_PER_CONNECTION=4 \
-x NCCL_IB_TC=160 \
-x LD_LIBRARY_PATH=$LD_LIBRARY_PATH \
-x PATH=$PATH \
-mca coll_hcoll_enable 0 \
-mca pml ob1 \
-mca btl_tcp_if_include eth0 \
-mca btl ^openib \
all_reduce_perf -b 1M -e 8G -f 2 -g 1由于opnempi是通过ssh远程命令拉起其他节点的进程的,所以上述192.168.1.72和192.168.1.73需要对应做免密登录,如果ssh端口不是默认的22端口那么还需要增加参数-mca plm_rsh_args "-p 端口号"
上述命令参数解释如下:
H host列表: 后指定每台机器要用的 GPU数量
--bind-to none:此选项告诉 MPI 不要将进程绑定到特定的 CPU 核心。这在某些情况下可能会提高性能
-map-by slot:表示任务会按照 slot 的顺序分配到节点上
-x <VARNAME>:将环境变量传递给 MPI 程序
NCCL_DEBUG=INFO:这个选项设置了NCCL的调试级别为INFO
NCCL_IB_GID_INDEX=3:这个选项设置了InfiniBand网络的GID索引为 3
NCCL_IB_DISABLE=0:这个选项表示不禁用InfiniBand网络
NCCL_SOCKET_IFNAME=eth0:这个选项指定了NCCL使用eth0网络接口进行通信
NCCL_NET_GDR_LEVEL=2:这个选项设置了 GPU Direct RDMA 的级别为 2
NCCL_IB_QPS_PER_CONNECTION=4:这个选项设置了每个连接的队列对数为 4
NCCL_IB_TC=160:这个选项设置了 InfiniBand 的流量类别为 160
LD_LIBRARY_PATH 和 PATH:这些选项将当前shell的LD_LIBRARY_PATH和PATH环境变量传递给mpirun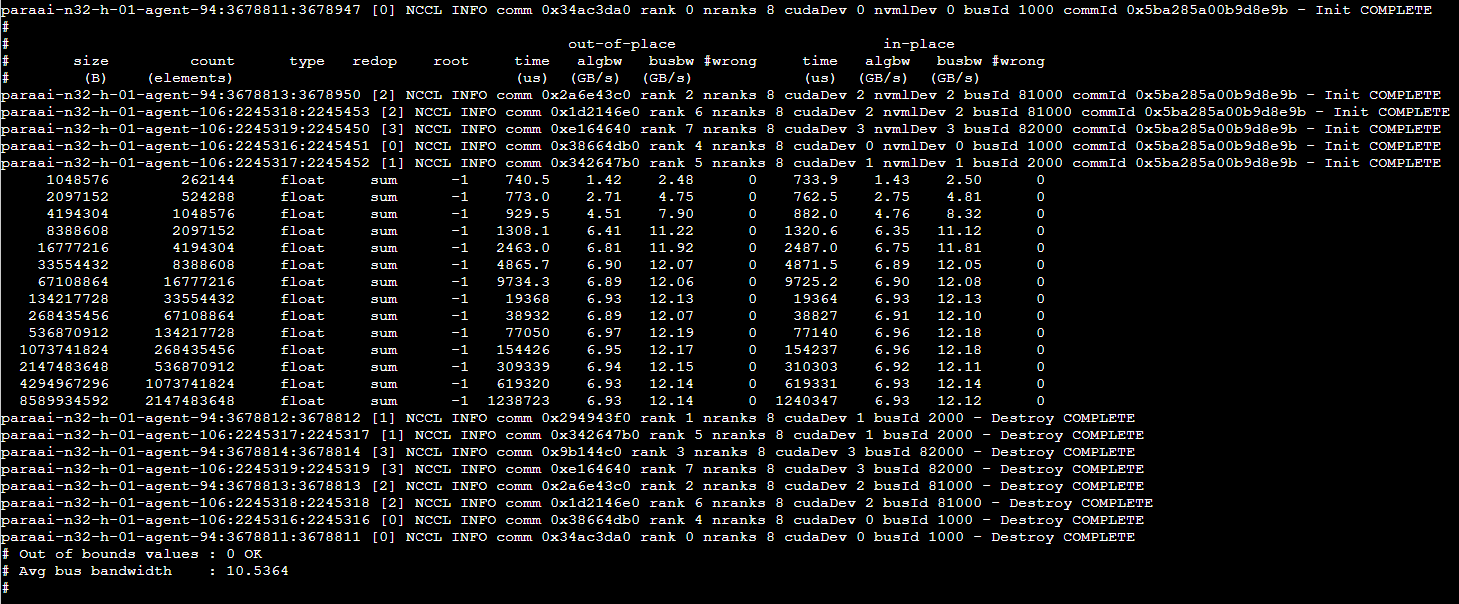
然后就是返回结果字段解释
size (B):操作处理的数据的大小,以字节为单位。在这个例子中,第一次操作处理了 33554432 字节(约 32MB)的数据,第二次操作处理了 133554432 字节(约 127MB)的数据。
count (elements):操作处理的元素的数量。在这个例子中,第一次操作处理了 8388608 个元素,第二次操作处理了 33388608 个元素。
type:元素的数据类型。在这个例子中,元素的数据类型是 float。
redop:使用的归约操作。在这个例子中,使用的归约操作是 sum(求和)。
root:对于某些操作(如 reduce 和 broadcast),这列指定了根节点的编号。在这个例子中,这列的值是 -1,这表示这个操作没有根节点(这是因为 all-reduce 操作涉及到所有的节点)。
time (us):操作的执行时间,以微秒为单位。这个列有两个值,分别表示两次不同的测量结果。
algbw (GB/s):算法带宽,以每秒吉字节(GB/s)为单位。这个列有两个值,分别表示两次不同的测量结果。
busbw (GB/s):总线带宽,以每秒吉字节(GB/s)为单位。这个列有两个值,分别表示两次不同的测量结果。
wrong:错误的数量。如果这个值不是 0,那么这可能表示有一些错误发生。内容版权声明:除非注明,否则皆为本站原创文章。
转载注明出处:https://sulao.cn/post/988
相关阅读
- GPU服务器dmesg日志报错"Cannot map memory with base addr ..."的解决方案
- ubuntu24.04卸载apt安装的驱动nccl和cuda库
- AI程序索引越界引起的nvidia-fabricnamage异常问题排查
- 英伟达GPU内核和驱动优化参数介绍
- 英伟达GPU nvidia-smi常用命令详解
- openmpi编译缺少libz压缩库导致的多机多卡测试失败问题解决方法
- GPU卡住且dmesg日志中打印NVRM: _threadNodecheckTimeout错误排查
- linux下gpu降速问题排查
- ubuntu22.04安装dcgm和基本用法
- RTX 5090在cuda13.0下gpu-burn编译报错的解决方法
评论列表