

此前没有了解过LoRA模型,可以能是由于接触的比较偏底层,最近接触所以查了一些资料并记录下来,接下来让我们来了解下LoRA模型是什么,并且它有哪些作用。首先LoRA我称之为模型,实际这是个很主观的叫法,LoRA(Low-...
此前没有了解过LoRA模型,可以能是由于接触的比较偏底层,最近接触所以查了一些资料并记录下来,接下来让我们来了解下LoRA模型是什么,并且它有哪些作用。首先LoRA我称之为模型,实际这是个很主观的叫法,LoRA(Low-...
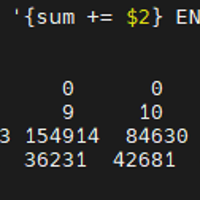
今天有同事反馈有请求报错502,我于是检查系统上的日志发现有如下错误信息[Thu Jun 18 23:15:31 2026] NVRM: _threadNodeCheckTimeout: _threadNodeCheck...
lark实际就是飞书的国际版,目前使用了lark机器人,常用的有两种机器人,一种是普通机器人,另外一种就是具有对话能力的机器人,实际第二种机器人就是第一种机器人增加了一些能力而已,当然还有其他能力也可以添加给机器人,但是...
我们此前使用OpenAI接口流式传输时,是通过一个[DONE]的标记来判断流的结束,但是目前接触到更多的LLM模型,然后遇到没有[DONE]标识的情况,所以查询了一些资料,我们此前的方法并不是OpenAI 标准流式接口消...
当你选择为Kubernetes控制平面(Master节点)的高可用(HA)使用kube-vip后,通常就不再需要额外部署Keepalived、HAProxy或Nginx来做API Server的负载均衡和高可用了。简单来...
ubuntu部署k8s无VIP多Master部署方案,默认使用IPVS,这种方案的优势在于无需机房网络这块再多划分VIP地址段,不需要ARP生成VIP,所以也就不需要同二层广播域(同一个内网二层网段),交换机ARP无拦截...
目前在MAAS服务中很多地方都需要设置更长的超时时间,是由于有时有超长的提示词导致需要更长的响应时间,这样需要更改Ingress的超时配置,Ingress的超时配置默认是60s,一般有两种配置方式可以调整这个超时时间1....
ServiceMonitor 是 Prometheus Operator 提供的一种 K8s 自定义资源(CRD),用来 “声明式” 地告诉 Prometheus 要监控哪些 Service,我们此前也记录了一篇部署pr...
我们最近遇到很多系统需要启动很久才能进入系统的情况,实际这个我们如果在有IPMI管理的情况下可以进入虚拟KVM控制台查看到应该是有某些systemd服务异常导致一致卡在某一个阶段导致,当重试多次启动失败以后才会进入系统。...
我们有时会遇到带IB网卡的GPU机器RDMA设备名不一样的问题,这种情况就会影响我们的正常使用,所以这个时候需要我们对RDMA设备名字进行修改注意我们此次涉及到两个名字,一个是RDMA设备名,一个是IB网卡名,他们是不同...
默认 kube-scheduler 用的是 LeastRequested:空闲越多越优先,我们需要改成:MostAllocated(已用越多、得分越高、越优先)。我们目前想根据线上环境调整下策略,实际需求就是使用GPU的...
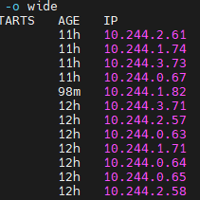
我的需求是使用loki存储数据,然后最后在grafana中展示,目前grafana已经部署好了,所以我们需要部署loki,我记得我此前工作一家公司是loki+promtail的组合,但是目前查询到promtail没有维护...
近期,Theori / Xint Code 公开披露 Linux 内核漏洞 Copy Fail(CVE-2026-31431)。该漏洞存在于 Linux 内核加密子系统相关逻辑中,攻击者在获得本地普通用户权限后,可通过 ...
此前我们记录过一个ubuntu22.04关闭自动更新服务,具体可以查看这里https://sulao.cn/post/1074,但是那个有交付的操作不方便整合到脚本中,然后今天就记录下禁止自动更新相关服务的配置。sudo...
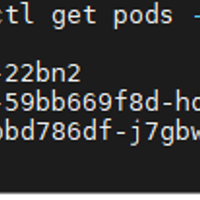
在没有 cert-manager 的情况下,你需要手动申请证书、创建 Kubernetes Secret,并在证书到期前重复这一流程,过程繁琐且容易出错。cert-manager 的核心价值在于:自动化:它会自动向 Le...
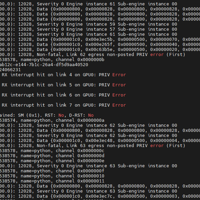
这两天客户反馈程序跑到一半异常了,然后查看dmesg日志有打印有很多nvswitch的12028的致命错误信息,还有Xid 94 和 137的错误信息,相关Xid 错误信息可以在这个笔记里面进行查询核对:https://...
在做具体操作之前我们来了解下ACS,ACS是指PCI访问控制服务(PCI Access Control Service),是一种在启用VT-d(I/O虚拟化技术)时用于控制PCI设备访问权限的机制,属于BIOS芯片组配置...