
这两天客户反馈程序跑到一半异常了,然后查看dmesg日志有打印有很多nvswitch的12028的致命错误信息,还有Xid 94 和 137的错误信息,相关Xid 错误信息可以在这个笔记里面进行查询核对:https://sulao.cn/post/1117
dmesg里面有如下信息:
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch1: SXid (PCI:0000:06:00.0): 12028, Data {0x000001c0, 0x000e265f, 0x00000500, 0x00000040, 0x00000000, 0x00008000, 0x5a000100, 0x00000000, 0x00000000}
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch3: SXid (PCI:0000:08:00.0): 12028, Data {0x000001c0, 0x00c63b5e, 0x00000500, 0x00000020, 0x00000000, 0x00008000, 0x5a002100, 0x00000000, 0x00000000}
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch2: SXid (PCI:0000:07:00.0): 12028, Non-fatal, Link 62 egress non-posted PRIV error (First)
[Mon Feb 2 22:52:45 2026] NVRM: Xid (PCI:0000:cb:00): 94, pid=538578, name=python, channel 0x0000000b
[Mon Feb 2 22:52:45 2026] NVRM: GPU at PCI:0000:4c:00: GPU-45eab12c-e144-7b1c-26a4-df5d9aa40520
[Mon Feb 2 22:52:45 2026] NVRM: GPU Board Serial Number: 1652724066231
[Mon Feb 2 22:52:45 2026] NVRM: Xid (PCI:0000:4c:00): 137, TLC RX interrupt hit on link 4 on GPU0: PRIV Error
[Mon Feb 2 22:52:45 2026] NVRM: Xid (PCI:0000:4c:00): 137, TLC RX interrupt hit on link 5 on GPU0: PRIV Error
[Mon Feb 2 22:52:45 2026] NVRM: Xid (PCI:0000:4c:00): 137, TLC RX interrupt hit on link 6 on GPU0: PRIV Error
[Mon Feb 2 22:52:45 2026] NVRM: Xid (PCI:0000:4c:00): 137, TLC RX interrupt hit on link 7 on GPU0: PRIV Error
[Mon Feb 2 22:52:45 2026] NVRM: Xid (PCI:0000:4c:00): 94, Contained: SM (0x1). RST: No, D-RST: No
[Mon Feb 2 22:52:45 2026] NVRM: Xid (PCI:0000:4c:00): 94, pid=538574, name=python, channel 0x0000000a
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch2: SXid (PCI:0000:07:00.0): 12028, Severity 0 Engine instance 62 Sub-engine instance 00
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch2: SXid (PCI:0000:07:00.0): 12028, Data {0x00000800, 0x00000828, 0x00000800, 0x00000828, 0x00000000, 0x00000000, 0x00000000, 0x00000000, 0x00000000}
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch2: SXid (PCI:0000:07:00.0): 12028, Severity 0 Engine instance 62 Sub-engine instance 00
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch2: SXid (PCI:0000:07:00.0): 12028, Data {0x000001c0, 0x00e3ec48, 0x00000500, 0x00000004, 0x00000000, 0x00008000, 0x5a000100, 0x00000000, 0x00000000}
[Mon Feb 2 22:52:45 2026] nvidia-nvswitch2: SXid (PCI:0000:07:00.0): 12028, Non-fatal, Link 63 egress non-posted PRIV error (First)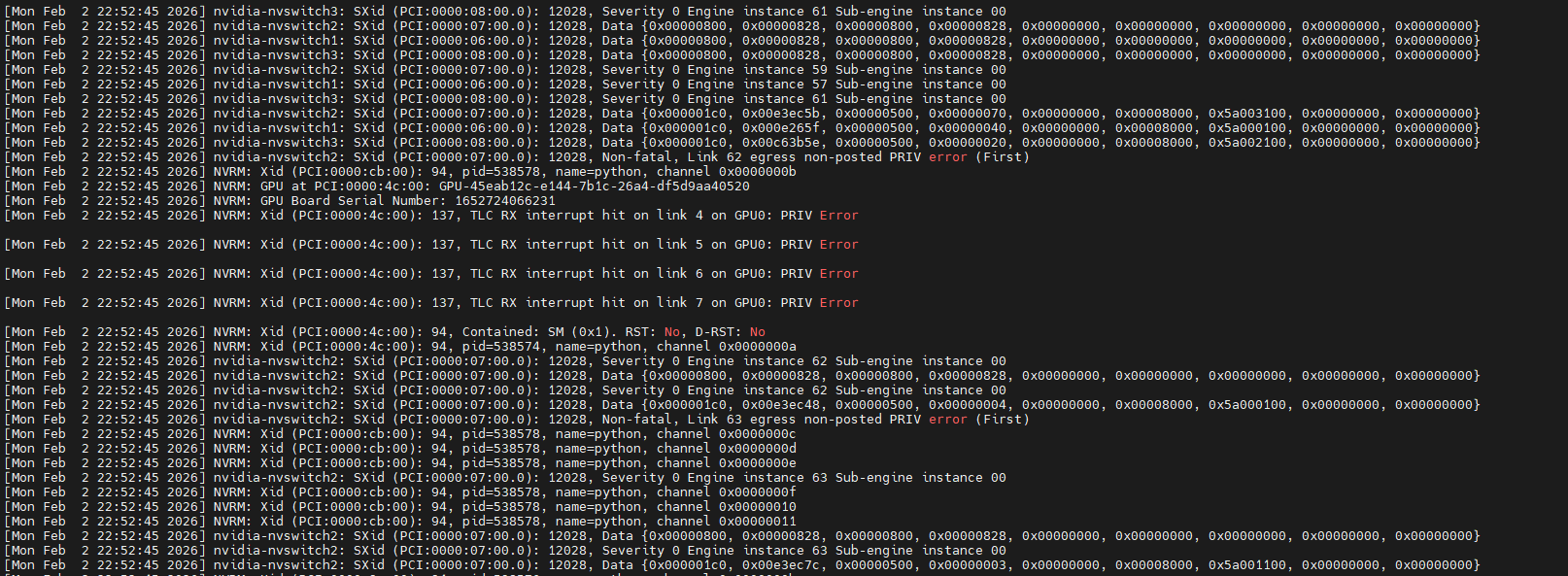
第一直觉是感觉nvllink故障了,看到PRIV Error看起来是权限错误,这个对应Xid 137,这种错误是表示GPU通过NVLink通信时访问权限违规,影响多卡通信,导致任务失败。而Xid 94通常跟ECC有关,使用如下命令检查ECC没有计数错误
nvidia-smi -q -d ECC然后检查nvidia-fabricmanager状态
systemctl status nvidia-fabricmanager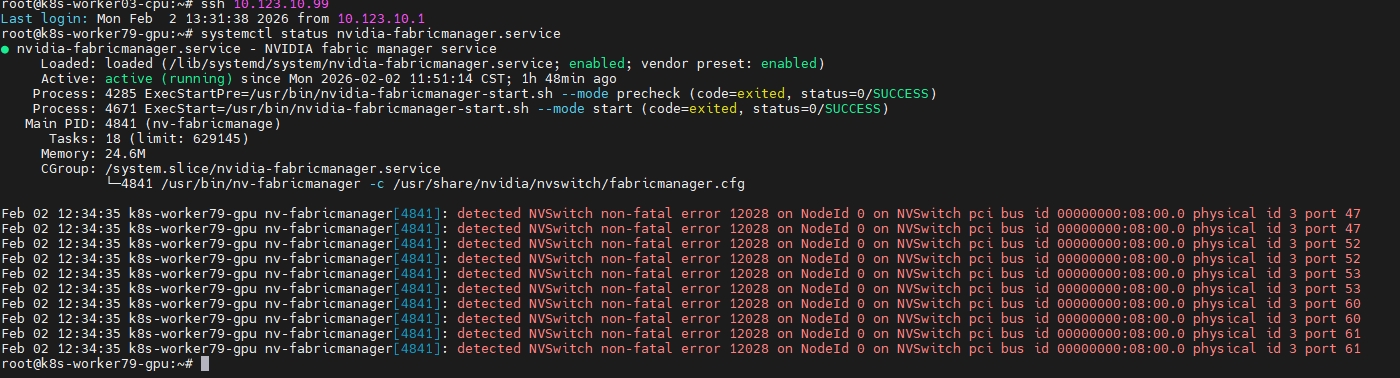
可以看到GPU卡id 3的卡nvlink出现致命错误。
起初怀疑硬件故障,于是联系厂家进行设备压测,然后通过几个小时的压测发现没有任何硬件发现的异常,然后只能接着分析,看看是否跟bios设置相关,然后定位到这些配置,这些配置跟其他节点存储不一致的问题,我们随即进行修改
Intel VT for Directed I/O (VT-d) 开启
H100 GPU使用PCIe进行数据传输,VT-d管理DMA(直接内存访问)
- 启用VT-d允许GPU直接访问系统内存
- 如果禁用,可能导致NVLink通信中断
- H100集群通常需要IOMMU支持,VT-d是基础
X2APIC Opt Out 关闭
- X2APIC支持更多的中断向量(最多64K)
- H100和NVSwitch会产生大量中断
- X2APIC Opt Out设置为Disabled时,系统使用X2APIC模式
- 旧APIC(256个中断)可能导致中断风暴和NVLink错误
Extended APIC 开启
- 扩展APIC功能增强中断处理能力
- 在多GPU环境中尤其重要
- 配合X2APIC使用,确保中断正确路由
PRM Size 设置2G
- PRM为特定功能预留内存
- 过大设置会减少GPU可用系统内存
- 可能导致GPU内存映射空间不足
SW Guard Extensions (SGX) 关闭
- SGX预留大量受保护内存
- 可能干扰GPU的大页内存分配
- HPC应用通常不需要SGX关机调整了以上配置以后然后让客户继续跑训练任务进行观察,然后跑了一百多个step以后问题再次复现
然后这次我就开始怀疑客户AI代码可能有问题触发的,前面硬件和bios设置都已经进行过调整,不太可能有什么环境和设置问题,开始查看客户代码详细报错,然后看到以下错误信息
/pytorch/aten/src/ATen/native/cuda/IndexKernelUtils.cu:16: vectorized_gather_kernel: block: [516,0,0], thread: [29,0,0] Assertion `ind >=0 && ind < ind_dim_size && "vectorized gather kernel index out o
f bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/IndexKernelUtils.cu:16: vectorized_gather_kernel: block: [516,0,0], thread: [30,0,0] Assertion `ind >=0 && ind < ind_dim_size && "vectorized gather kernel index out o
f bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/IndexKernelUtils.cu:16: vectorized_gather_kernel: block: [516,0,0], thread: [31,0,0] Assertion `ind >=0 && ind < ind_dim_size && "vectorized gather kernel index out o
f bounds"` failed.
[rank7]: Traceback (most recent call last):
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/examples/z_image/model_training/train.py", line 153, in <module>
[rank7]: launcher_map[args.task](accelerator, dataset, model, model_logger, args=args)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/diffsynth/diffusion/runner.py", line 78, in launch_training_task
[rank7]: loss = model(data)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
[rank7]: return self._call_impl(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
[rank7]: return forward_call(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1661, in forward
[rank7]: else self._run_ddp_forward(*inputs, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1487, in _run_ddp_forward
[rank7]: return self.module(*inputs, **kwargs) # type: ignore[index]
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
[rank7]: return self._call_impl(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
[rank7]: return forward_call(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/accelerate/utils/operations.py", line 819, in forward
[rank7]: return model_forward(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/accelerate/utils/operations.py", line 807, in __call__
[rank7]: return convert_to_fp32(self.model_forward(*args, **kwargs))
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 44, in decorate_autocast
[rank7]: return func(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/examples/z_image/model_training/train.py", line 88, in forward
[rank7]: loss = self.task_to_loss[self.task](self.pipe, *inputs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/examples/z_image/model_training/train.py", line 48, in <lambda>
[rank7]: "sft": lambda pipe, inputs_shared, inputs_posi, inputs_nega: FlowMatchSFTLoss(pipe, **inputs_shared, **inputs_posi),
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/diffsynth/diffusion/loss.py", line 17, in FlowMatchSFTLoss
[rank7]: noise_pred = pipe.model_fn(**models, **inputs, timestep=timestep)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/diffsynth/pipelines/z_image.py", line 248, in model_fn_z_image
[rank7]: model_output = dit(
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1775, in _wrapped_call_impl
[rank7]: return self._call_impl(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1786, in _call_impl
[rank7]: return forward_call(*args, **kwargs)
[rank7]: File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/diffsynth/models/z_image_dit.py", line 568, in forward
[rank7]: cap_feats[torch.cat(cap_inner_pad_mask)] = self.cap_pad_token.to(dtype=x.dtype, device=x.device)
[rank7]: torch.AcceleratorError: CUDA error: device-side assert triggered
[rank7]: Search for `cudaErrorAssert' in https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html for more information.
[rank7]: CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
[rank7]: For debugging consider passing CUDA_LAUNCH_BLOCKING=1
[rank7]: Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.这个错误看起来是 ind 索引超出了范围。
可能是因为索引越界导致GPU内存访问错误,进而触发NVLink保护机制。大概是程序本身存在bug,导致索引计算错误。
然后这个错误感觉可以串起来
CUDA错误 → GPU状态异常 → NVLink通信错误
然后使用CUDA调试环境变量再次运行
export CUDA_LAUNCH_BLOCKING=1 # 同步执行CUDA kernel,便于调试
export TORCH_USE_CUDA_DSA=1 # 启用设备端断言
export CUDA_DEVICE_MAX_CONNECTIONS=1 # 限制CUDA连接数
export NCCL_DEBUG=INFO # 启用NCCL调试信息然后运行脚本跑了2-300个step以后有如下报错
uv run sh examples/z_image/model_training/lora/Z-Image.sh
[2026-02-03 00:00:11] 4516db9ebeec94bc7ca6e8963e3538c7-taskrole1-0:1774:2239 [7] init.cc:2149 NCCL WARN commReclaim: cleanup comm 0x55e6dcd50dc0 rank 7 failed in destroy/abort, error 1
W0203 00:00:12.818000 1699 torch/distributed/elastic/multiprocessing/api.py:908] Sending process 1767 closing signal SIGTERM
W0203 00:00:12.820000 1699 torch/distributed/elastic/multiprocessing/api.py:908] Sending process 1768 closing signal SIGTERM
W0203 00:00:12.821000 1699 torch/distributed/elastic/multiprocessing/api.py:908] Sending process 1769 closing signal SIGTERM
W0203 00:00:12.822000 1699 torch/distributed/elastic/multiprocessing/api.py:908] Sending process 1770 closing signal SIGTERM
W0203 00:00:12.822000 1699 torch/distributed/elastic/multiprocessing/api.py:908] Sending process 1771 closing signal SIGTERM
W0203 00:00:12.824000 1699 torch/distributed/elastic/multiprocessing/api.py:908] Sending process 1772 closing signal SIGTERM
W0203 00:00:12.825000 1699 torch/distributed/elastic/multiprocessing/api.py:908] Sending process 1773 closing signal SIGTERM
E0203 00:00:12.827000 1699 torch/distributed/elastic/multiprocessing/api.py:882] failed (exitcode: 1) local_rank: 7 (pid: 1774) of binary: /gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/bin/python
Traceback (most recent call last):
File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/bin/accelerate", line 10, in <module>
sys.exit(main())
File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py", line 50, in main
args.func(args)
File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/accelerate/commands/launch.py", line 1272, in launch_command
multi_gpu_launcher(args)
File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/accelerate/commands/launch.py", line 899, in multi_gpu_launcher
distrib_run.run(args)
File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/distributed/run.py", line 927, in run
elastic_launch(
File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 156, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/gemini/platform/public/aigc/aigc_image/zhoulx/cp_from_data05/DiffSynth-Studio-2511/.venv/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 293, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
examples/z_image/model_training/train.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2026-02-03_00:00:12
host : 4516db9ebeec94bc7ca6e8963e3538c7-taskrole1-0
rank : 7 (local_rank: 7)
exitcode : 1 (pid: 1774)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================上述错误信息表明启用了同步调试模式后,分布式训练出现了超时或通信问题。
然后还是借助了AI的力量,拿到以下测试代码进行问题验证测试
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import os
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def test_gather_operation(rank, world_size):
setup(rank, world_size)
device = torch.device(f'cuda:{rank}')
torch.cuda.set_device(device)
# 模拟可能出错的gather操作
batch_size = 8
seq_len = 256
hidden_size = 768
# 创建特征张量
cap_feats = torch.randn(batch_size, seq_len, hidden_size, device=device)
# 创建可能包含非法值的mask
# 模拟数据加载错误:产生负索引
cap_inner_pad_mask = []
for i in range(batch_size):
# 有时产生非法索引
if rank == 7 and i == 0: # GPU 6的第一个样本有问题
# 产生负索引
mask = torch.randint(-5, 5, (10,), device=device)
else:
# 正常索引
mask = torch.randint(0, seq_len, (10,), device=device)
cap_inner_pad_mask.append(mask)
# 模拟出问题的操作
indices = torch.cat(cap_inner_pad_mask)
print(f"Rank {rank}: indices shape {indices.shape}, range [{indices.min()}, {indices.max()}]")
# 检查是否有非法索引
if (indices < 0).any() or (indices >= seq_len).any():
print(f"Rank {rank}: Found illegal indices!")
# 修复索引
indices = torch.clamp(indices, 0, seq_len - 1)
print(f"Rank {rank}: Fixed indices to range [0, {seq_len-1}]")
# 执行赋值
cap_feats[indices] = 0
print(f"Rank {rank}: Test completed successfully")
cleanup()
if __name__ == "__main__":
world_size = 8
# 使用torch.multiprocessing启动
import torch.multiprocessing as mp
mp.spawn(test_gather_operation, args=(world_size,), nprocs=world_size, join=True)上述打印如下
Rank 4: indices shape torch.Size([80]), range [5, 250]
Rank 4: Test completed successfully
Rank 2: indices shape torch.Size([80]), range [3, 250]
Rank 5: indices shape torch.Size([80]), range [8, 255]
Rank 2: Test completed successfully
Rank 5: Test completed successfully
Rank 0: indices shape torch.Size([80]), range [9, 255]
Rank 0: Test completed successfully
Rank 6: indices shape torch.Size([80]), range [0, 255]
Rank 6: Test completed successfully
Rank 3: indices shape torch.Size([80]), range [3, 254]
Rank 7: indices shape torch.Size([80]), range [-5, 254]
Rank 7: Found illegal indices!
Rank 1: indices shape torch.Size([80]), range [0, 244]
Rank 3: Test completed successfully
Rank 7: Fixed indices to range [0, 255]
Rank 7: Test completed successfully
Rank 1: Test completed successfully可以看到索引是-5的时候触发了断言错误,根据上述代码基本可以实锤是程序问题触发的。
然后根据上面日志定位到具体代码位置,添加代码索引边界检查,最后程序再次运行起来就没有再次出现触发nvidia-fabricmanager异常问题。
- 标签
- ai
- gpu
- nvidia
- fabricmanager
内容版权声明:除非注明,否则皆为本站原创文章。
转载注明出处:https://sulao.cn/post/1165
相关阅读
- GPU服务器dmesg日志报错"Cannot map memory with base addr ..."的解决方案
- OpenAI原生SSE协议流式接口传输结束的判断方法
- ubuntu24.04卸载apt安装的驱动nccl和cuda库
- linux内核无法加载nvidia-peermem模块的问题分析
- 英伟达GPU内核和驱动优化参数介绍
- 英伟达GPU nvidia-smi常用命令详解
- GPU卡住且dmesg日志中打印NVRM: _threadNodecheckTimeout错误排查
- linux下gpu降速问题排查
- linux重新构建软raid其中一块盘一直rebuilding的解决方法
- ubuntu22.04安装dcgm和基本用法
评论列表