flask工厂函数主要是用来动态创建应用实例的,我们在一般应用中都需要将peewee数据库初始化的动作放到这个工厂函数里,之前有学习过使用sqlalchemy集成到工厂函数,可以查看这个笔记:http://www.sul...
flask工厂函数主要是用来动态创建应用实例的,我们在一般应用中都需要将peewee数据库初始化的动作放到这个工厂函数里,之前有学习过使用sqlalchemy集成到工厂函数,可以查看这个笔记:http://www.sul...
在使用 Flask 和 Peewee 操作数据库时,确保数据库连接在使用后正确关闭非常重要。Peewee 提供了几种方式来自动管理数据库连接的生命周期。以下是几种常见的方法:1.使用flask钩子可以在请求上下文前后开启...
模型内部的结构和组成因类型而异,但以常见的深度学习模型(如神经网络)为例,其核心组成部分和机制可以总结如下:1.基本结构组件输入层(Input Layer):接收原始数据(如文本、图像、数值),并将其转换为模型可处理的格...
大模型通常指的大语言模型,这个大主要体现在规模上,一般指的参数规模和包含更复杂的神经网络架构,目前模型主要有包括Transformer、卷积神经网络(CNN)和循环神经网络(RNN)这几种模型架构。一般模型训练是为了通过...
由于手游挂机需要充值月卡,手头比较紧,没有钱充值,所以研究了下月卡相关的内存特征代码,用按键精灵写了个开启的脚本,目前还是存在开启失败的情况,大概成功率在90%左右,如果开启失败就重启模拟器以后再开启进入游戏进行再次开启...
strace命令是一个集诊断、调试、统计于一体的工具,我们可以用它来监控用户空间进程和内核的交互。比如对应用程序的系统调用、信号传递与进程状态变更等进行跟踪与分析,以达到解决问题的目的。strace常用来跟踪进程执行时的...
按键精灵目前关于内存操作的一些文章比较少,网上讲的基本都是同一个游戏获取坐标的那个教程,里面讲的东西也感觉还是不清楚,所以这里我自己记录一个自己在使用的脚本获取角色信息的方法。目前一些外挂主要使用过修改游戏内存数据达到篡...
最近在研究内存相关的数据存储,发现有些浮点数存在于内存中是一个10位长度的数字,后面研究得知是基于754标准转换到16进制,然后再转为10进制就是10位的长度,所以这里记录下来,方便后续研究。#!/usr/bin/pyt...
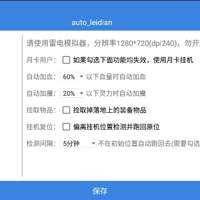
此次在之前的脚本基础上增加了一些功能,例如挂机时角色自动跑到了偏离原有挂机位置很远的地方,这个时候就需要进行复位原来挂机坐标,另外也增加了每个技能的CD延迟设置功能,这样确保在某些地图挂机只是用自己需要的技能和对应的CD...

这次还是在上次脚本的基础功能上,增加了自动售卖装备和清理药水的功能,需要角色是至尊账户,因为是开启的随身商店,要有至尊角色有这个功能,使用教程可以查看上次那个笔记:https://sulao.cn/post/992相对于...
通常在一个集群会有一个统一的API入口,一般都是使用nginx来做统一的入口代理,然后到后端再转发到对应的服务API上。今天就整合之前的一些代理的配置,方便后续使用。1.nginx代理http/https请求http {...
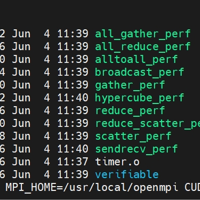
NCCL Tests是一个开源的测试套件,由NVIDIA开发并维护,目的是为了帮助开发者更好地理解和利用NCCL的功能。它提供了多种并发和消息传递模式的基准测试,以评估多GPU间的通信效率,并且支持各种CUDA和MPI环...
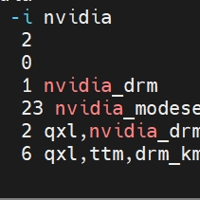
日常在一些程序中进行GPU调用,这些cuda程序异常崩溃的时候,有时会遇到掉卡掉驱动、没有进程但是显存被占用的情况,这个时候我们可以通过以下命令来尝试进行处理。如果是掉卡的话可以使用lspci查看下主板上还能否检测到GP...
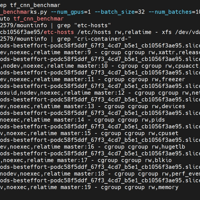
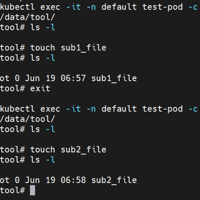
之前我们有记录过一个笔记,是docker环境下通过查看到的进程PID号来查找到拥有该进程的POD,具体可以查看我之前的笔记:https://sulao.cn/post/922近期基本都在将docker环境切换到conta...
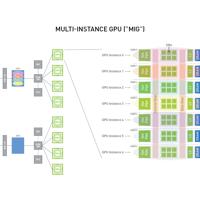
MIG通过虚拟地将单个物理GPU划分为更小的独立实例,这项技术涉及GPU虚拟化,GPU的资源,包括CUDA内核和内存,被分配到不同的实例。这些实例彼此隔离,确保在一个实例上运行的任务不会干扰其他实例。使用MIG,每个实例...
我们在k8s使用英伟达GPU时想让POD自动挂载我们需要部署nvidia-device-plugin组件,如何部署使用可以查看我之前的笔记:https://sulao.cn/post/975英伟达的device plug...
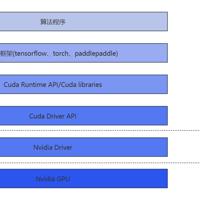
目前市面上有很多GPU共享技术,在GPU共享的模式下,在用户态共享和内核态进行共享是不一样的,根据以下视图,越往底层,共享对用户的影响越小,安全性也能对应提升。下面我就来简单介绍下目前GPU共享的一些技术1.CUDA劫持...