kafka单条发送消息大小的设置方法

在kafka的默认配置中,默认单条消息最大为1M,当单条消息长度超过1M时,就会出现发送到broker失败,从而导致消息在producer的队列中一直累积,直到撑爆生产者的内存当单条发送消息的大小超过1M,则会报一下错误ERROR Error when sending message to topic testTopic with key: null, value: 2095476 bytes with e...
在kafka的默认配置中,默认单条消息最大为1M,当单条消息长度超过1M时,就会出现发送到broker失败,从而导致消息在producer的队列中一直累积,直到撑爆生产者的内存当单条发送消息的大小超过1M,则会报一下错误ERROR Error when sending message to topic testTopic with key: null, value: 2095476 bytes with e...
目前在我的工作中删除topic这种操作基本很少去做,但是之前也做过几次,都是很粗暴的去目录下删除文件,移除目录等方法这次学习的笔记中我们学习记录如何彻底删除kafka的topic,按照一个正常的流程去操作,删除kafka的步骤有以下这些首先你需要停止订阅这个topic的所有消费者和生产者,如果不停止回导致broker一致更新消费者offset状态,直接调用kafka删除命令无法删除topic,同时auto.create.topics.enable的值设置为false,默认是true,如果不进行修改的话,没有完全停止生产者,生产者在没有topic的情况下回...
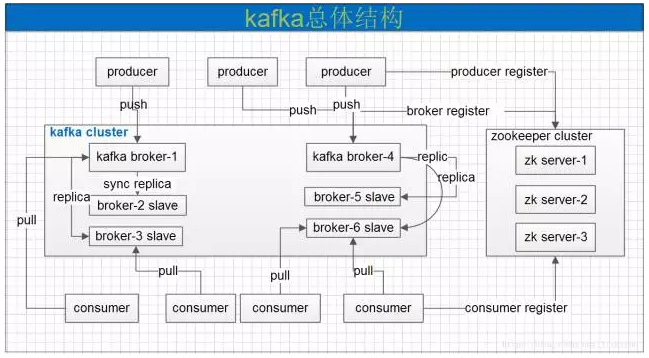
Kafka是一种分布式的、分区的、多副本的基于发布/订阅的消息系统。它是通过zookeeper进行协调,常见可以用于web/nginx日志、访问日志、消息服务等。主要应用场景为:日志收集系统和消息系统。Kafka的主要设计目标如下:1.以时间复杂度为O(1)的方式提供持久化能力,即使对TB级别以上的数据也能保证常数时间的访问性能。2.高吞吐率,即使在十分廉价的机器上也能实现单机支持每秒100K条消息的传输。3.支持KafkaServer(即Kafka集群的服务器)间的消息分区,及分布式消费,同时保证每个parti...
我们通过之前得学习,得知kafka一些特性和python操作kafka得方法,但是我们还没有学习过查看kafka数据方法,然后在这一篇笔记中我们来学习下使用命令来查看kafka数据我们首先查看kafka主题分布情况/usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic nginx-logsTopic:nginx-logs &...
考虑到发布和订阅消息的实时性问题,有时需要消费者重新消费之前的历史日志消息,所以后面肯定需要使用kafka替换掉原来使用的redis,所以这里暂时先mark下logstash清洗过滤日志以后发布到kafka主题中的方式将日志数据导入到kafkainput { beats { port => 5044 codec => plain { &...
因为kafkaManager支持对Kafka的主题的增删改查操作,和消费者对数据的消费情况。而kafkaMonitor对kafka新版(1.0版后),支持不太好,比如在Kafka1.1版中,用代码创建的Topic,地址没有直接绑定zookeeper,而是通过的bootstrap.server指定的Broker地址,间接绑定到zookeeper,在KafkaMonitor中却查看不到这些Topic,果断放弃了使用kafkaMonitor我们来看看kafka-manager的部署过程吧,目前最新版本还是2018年的kafka-manager-1.3....
之前有部署过kafka,但是用的比较少,以后可能用的比较多了,所以编写整理了下kafka和zookeeper的开机启动服务的编写之前部署的笔记可以查看这里:https://sulao.cn/post/489.html我部署的目录是/usr/local/kafka,脚本约定部署目录为此目录,如果不一样可以直接修改下面服务里的路径zookeeper开机启动服务脚本#vi /usr/lib/systemd/system/zookeeper.service [Unit]Description=zookeeper projec...
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。特性:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的...
之前有做单机版的kafka部署,现在没事在本地测试下kafka+zookeeper集群,目前节点信息如下192.168.128.134 master (kafka+zookeeper)192.168.128.135 node1 (kafka+zookeeper)192.168.128.137 node2 (kafka+zookeeper)每个节点都需要部署zookeeper进行相互间检查通讯下载kafka和zookeeper源码包wget http://mirrors.hust...
之前单机版的之前一直配置有问题,用的2.12的版本,jdk则安装的是1.8.0的,一直配置有错误,翻阅网上脚本也都是低版本的,今天重新测试了下2.11的最新版,很顺利,一遍就配置成功了,顺便写了个一键安装脚本,记录下#!/bin/bash#author merci#安装前先确保/etc/sysconfig/network内的HOSTNAME和/etc/hosts内的hostname一致#kafka部署系统最低内存建议不要低于2G#hosts主机名(network内的HOSTNAME一致)hname=`hostname`...