Tensorflow运行报错'Could not load dynamic library libcudnn.so.8'
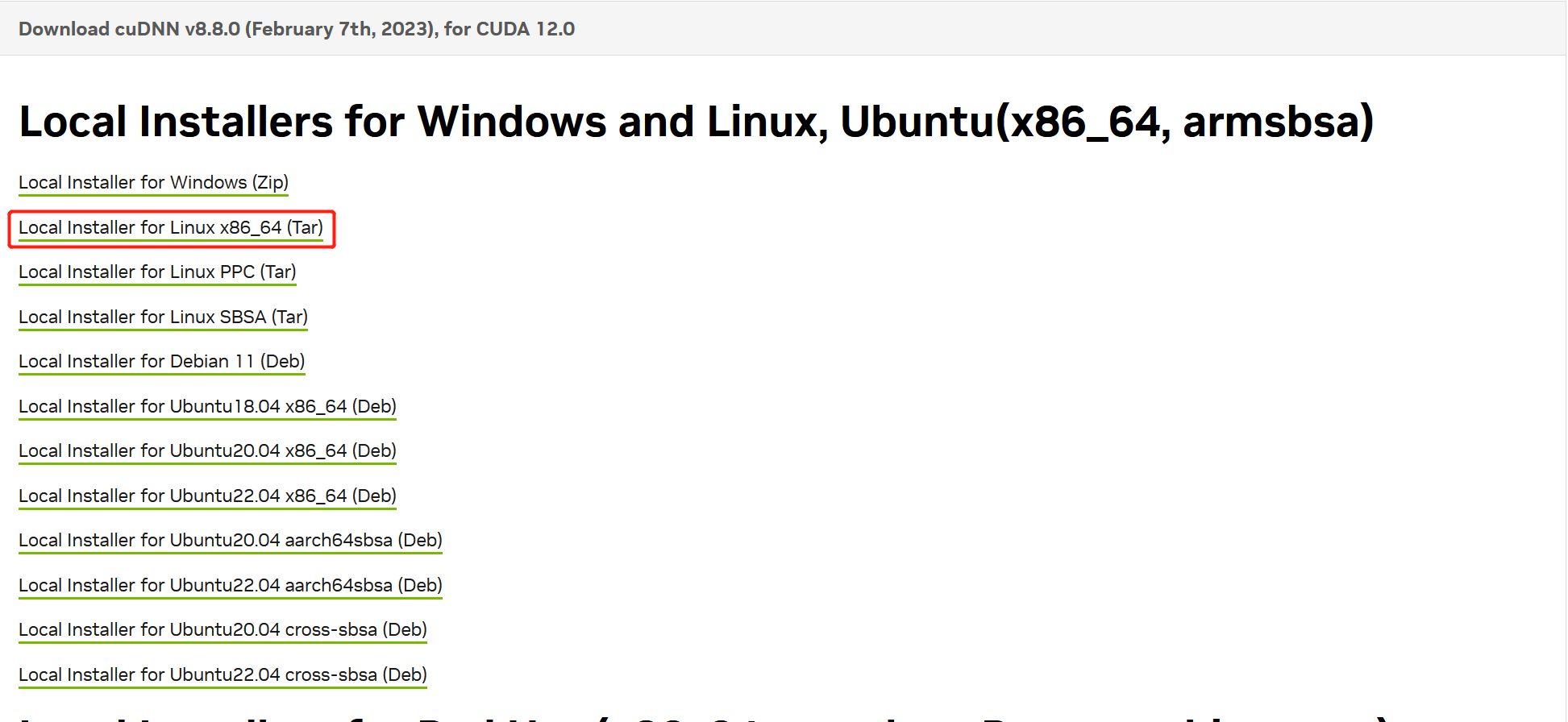
Tensorflow运行报错'Couldnotloaddynamiclibrarylibcudnn.so.8',该报错是由于没有cudnn导致,可以在https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html这个页面找到安装方法。cudnn文件可以在https://developer.nvidia.com/rdp/cudnn-archive去下载,注意需要下载对应cuda版本的cudnn我们如果cuda版本是12.0,则下载12.0下对应系统架构的tar...