python3是用shutil模块复制拷贝移动文件

shutil是高级的文件,文件夹,压缩包处理模块,我们来看看有哪些使用方法1.拷贝文件内容到另外一个文件shutil.copyfileobj(fsrc, fdst[, length])import shutilshutil.copyfileobj(open('test.txt', 'r', encoding='utf-8'), open('test.log', 'w', encoding...
shutil是高级的文件,文件夹,压缩包处理模块,我们来看看有哪些使用方法1.拷贝文件内容到另外一个文件shutil.copyfileobj(fsrc, fdst[, length])import shutilshutil.copyfileobj(open('test.txt', 'r', encoding='utf-8'), open('test.log', 'w', encoding...
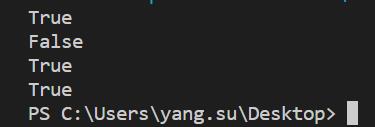
函数:startswith()作用:判断字符串是否以指定字符或子字符串开头一、函数说明语法:string.startswith(str, beg=0,end=len(string))或string[beg:end].startswith(str)参数说明:string: 被检测的字符串str: 指定的字符或者子字符串。(可以使用元组,会逐一匹配)beg: 设置字符串检测的起始位置(可选)e...
常用的小功能,收集目录下的图片,并将图片转成base64对象具体代码如下:#!/usr/bin/python3#coding:utf-8import osimport base64def file_list(path): files = [] d = os.walk(path) for parent,&nbs...
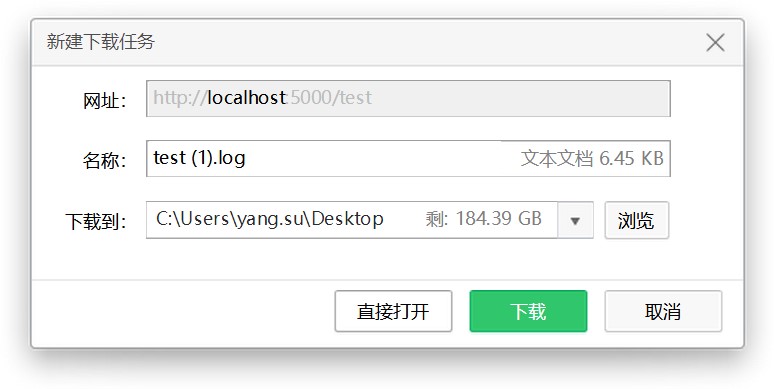
最近遇到一个需求,就是要生成csv或者是excel,然后提供下载,当时不是提前就备好了下载列表,而是需要根据需求来生成,之前也写过一个类似的php的笔记:https://sulao.cn/post/399.html好了,我们还是来看看flask的下载文件是如何实现的1.通过send_from_directory方法返回真实的文件from flask import Flask,request,send_from_directoryimport csvimport json@tools.rout...
今天想测试下爬虫框架,于是就pip进行安装发现报错,看下面提示error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools看上面感觉好像是需要安装v...

通常在Python中我们进行并发编程一般都是使用多线程或者多进程来实现的,对于计算型任务由于GIL的存在我们通常使用多进程来实现,而对与IO型任务我们可以通过线程调度来让线程在执行IO任务时让出GIL,从而实现表面上的并发。其实对于IO型任务我们还有一种选择就是协程,协程是运行在单线程当中的“并发”,协程相比多线程一大优势就是省去了多线程之间的切换开销,获得了更大的运行效率。Python中的asyncio也是基于协程来进行实现的。我们先来看如何创建协程和task任务import asyncioasync def te...
巩固下python基础知识,给大家介绍下递归并配上自己的例子,百度看别人说的很好,递归的概念和特点介绍等等就直接copy过来了递归算法是一种直接或间接调用自身算法的过程,在计算机编程中,递归算法对解决一大类问题是十分,它往往使算法的描述简洁而且易于理解。递归算法解决问题的特点:1.递归就是在过程或函数里调用自身2.在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。3.递归算法解题通常显得很简洁,但递归算法解题的运行效率较低,所以一般不提倡用递归算法设计程序。4.在递归调用的过程中系统为每一层的返回点、局部量等开辟了栈来存储,递归次数过多容易造...
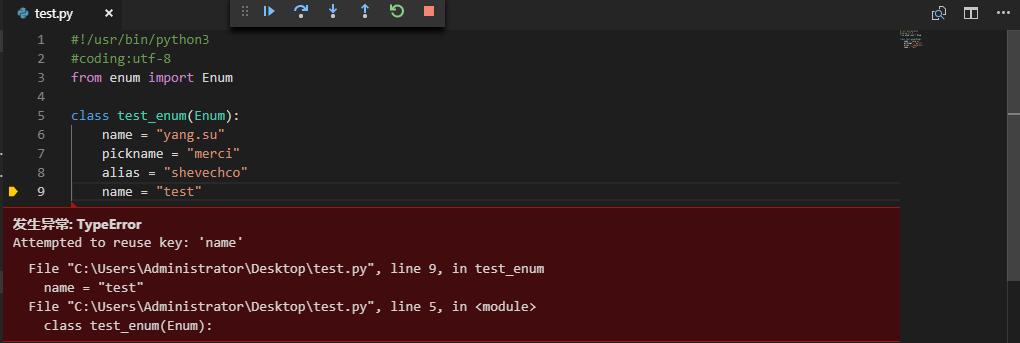
补一下python基础知识,枚举类型的详解,以及python中枚举的方法。首先我们需要知道什么叫枚举,以下我个人总结枚举一般就是把一个集合中对象一个个列举出来例如python中字典可以利用键值的关系枚举enum1 = { "name":"yang.su", "pickname":"merci", "...
之前的笔记讲的过程中一般都是使用queue队列来进行线程或者进程间进行通信或者资源的调配,但是我们大部分多进程和多线程的场景还是需要用到进程锁和线程锁,直接上例子,例子还是之前的csv模块用法的笔记:https://sulao.cn/post/597.html,还有python3进程间通信queue的用法https://sulao.cn/post/616.html这两个笔记的例子上改的,非百度copy的例子多进程代码实例:#!/usr/bin/python3#coding:utf-8from multiprocessing i...
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。特性:通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的...