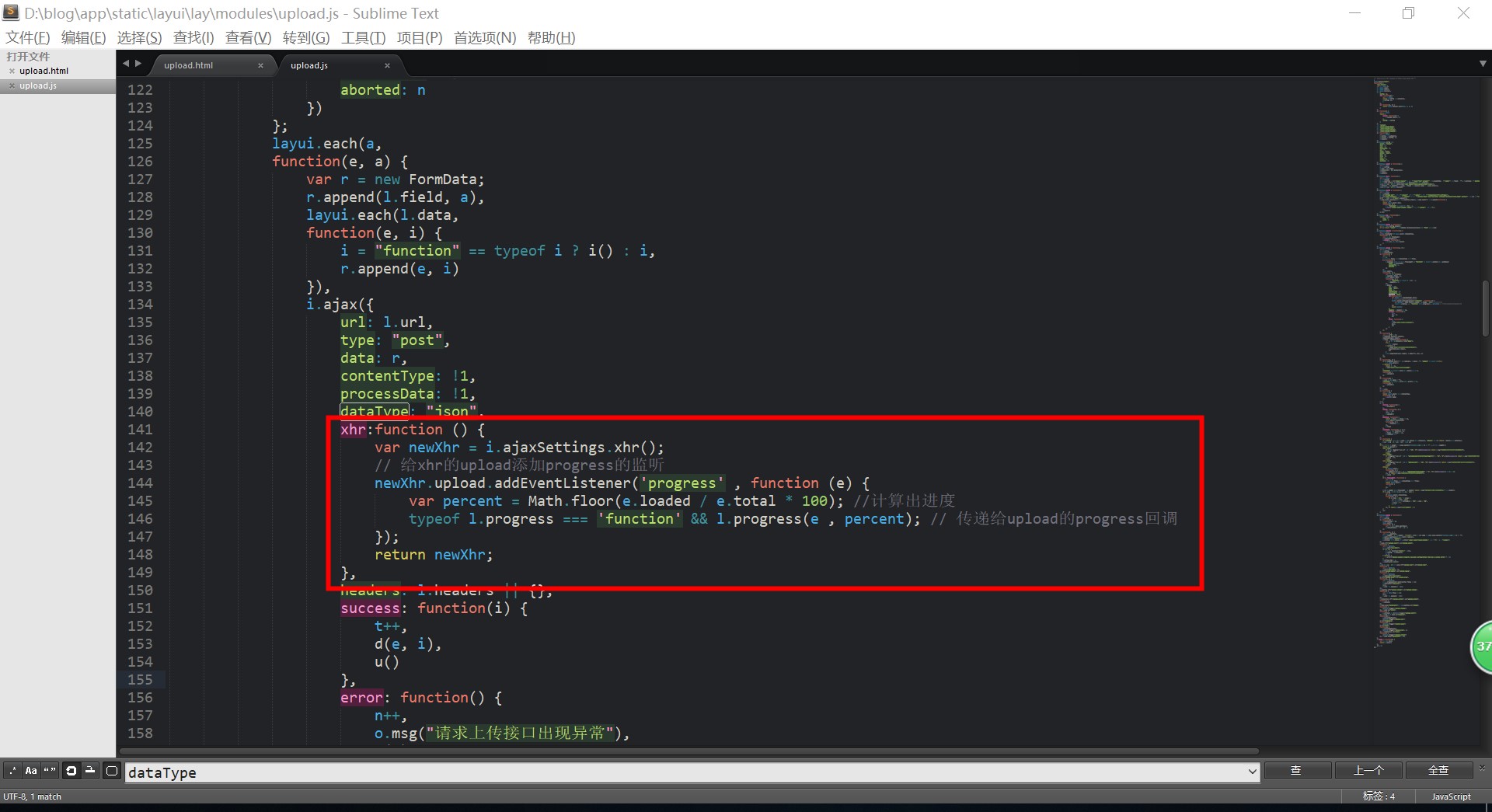
ThinkPHP5中raw的作用

在thinkphp5中,我们一般在模板中输出变量是这样的:{$test}但是有时候在有些源码中我们可以看到这样的方式:{$test|raw}这个时候如果你去找手册会发现,全文基本没有提到这个raw的作用。那么根据{}中|的作用理解,我们可以吧raw当成是一个方法,全局搜索试试。很遗憾,只在Query.php中找到一个同名方法,且这是一个类方法,PASS。后面直接在模板中写两个,分别是带raw和不带的,刷新页面,查看runtime中的缓存文件。结果一目了然,如下:{$test} ------> <?php echo...