CUDA库的安装和samples的使用方法
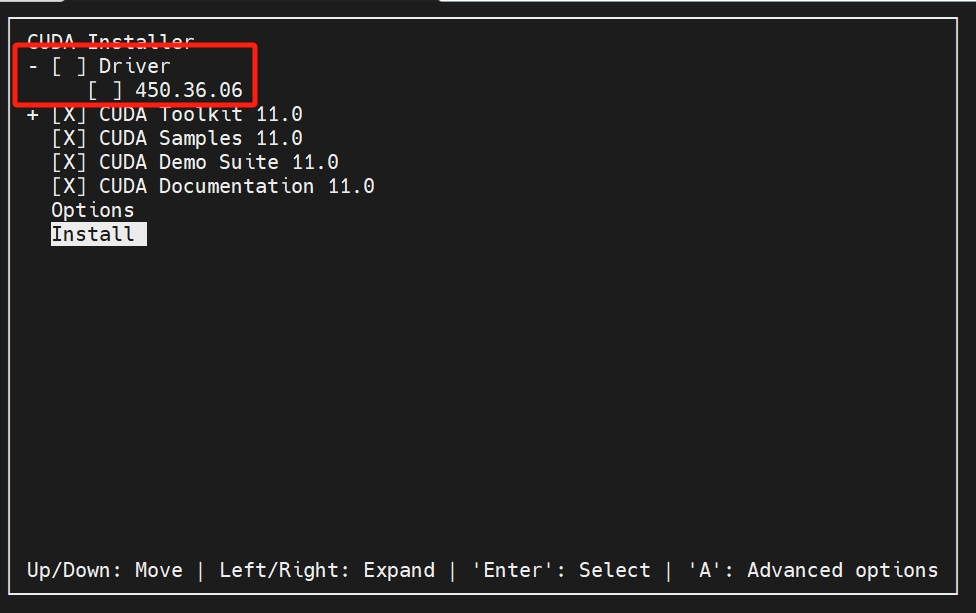
我们的环境是centos7,可以去官网下载指定版本的cuda库:https://developer.nvidia.com/cuda-toolkit-archive,我们这里以12.0的cuda库为例。wget https://developer.download.nvidia.com/compute/cuda/11.0.1/local_installers/cuda_11.0.1_450.36.06_linux.runsudo sh cuda_11.0.1_450.36.06_linux.run安装的时候我们就不再勾选D...